[AIFactory 세미나] 오픈소스 기반 LLM의 ChatGPT 추격 히스토리
영상 제목은 LLM 기반 챗봇 만들기이지만, 영상내용은 제목과 다르다.
- LLM 히스토리 / 오픈소스 진영에서 LLM Fine-tuning에 어떤 어려움을 겪었고 어떻게 해결방법을 찾고 있나
- 그렇게 만들어진 오픈소스 LLM에는 어떤 것들이 있나
- 수많은 오픈소스 LLM의 성능 비교는 어떻게 해야 하나
세 가지 질문을 대답해나가는 강연이라고 보면 된다. 내용이 쉽지는 않지만, LLM에 관심이 있다면 재미있게 들어볼 수 있다.
https://aifactory.space/learning/2419/discussion/339
[챗GPT 러닝데이 | 챗GPT말고 LLM] LLM 기반 챗봇 만들기 - 박찬성
ChatGPT 이후 Large Language Model(LLM)과 챗봇 서비스에 대한 관심이 급증하는 가운데, Meta AI에서 LLaMA라는 LLM을 공개했습니다. 이후 다양한
aifactory.space
영상: https://www.youtube.com/live/MKqTwv2B5rU?feature=share


LLM / OpenSource / Community 세 가지 관점.
- NLP 전문가는 아니므로, 개인적인 의견이 담긴 발표라고 이해해주셨으면 좋겠다고 함.

- 엔지니어 관점에서 LLM이 흥미로운 이유
- LLM을 유용하게 쓰기 위한 테크닉 / 시나리오 -> 오픈소스가 쓰는 방식은 어떤 것들이 있는지
- 오픈소스 생태계에서 많은 LLM 등장... 검증 안 된 것들 많음. 쓰려면 어떤 것들을 고려해야 할까
Why the topic of LLM?

LLM Ops는 작년 (2022년 말 무렵)부터 관심을 받기 시작한 것 같음.
- LLM을 어떻게 reliable, continuous하게 운영할 수 있는지.
- 모델 재학습 (Training)
- Fine Tuning
- 등등...
- MLOps와 비슷한 줄 알았는데, 본질적으로 달랐다.
- 압도적인 모델 사이즈에서 발생하는 문제 때문.
- 예컨대 visual transformer 모델은 CPU로도 충분히 서빙 가능했음. GPU까지 갈 일 없이 최적화 가능했음.
- 기존 MLOps에서 구축한 component의 capacity로는 불가능 - 재정의가 필요함.
- 압도적인 모델 사이즈에서 발생하는 문제 때문.
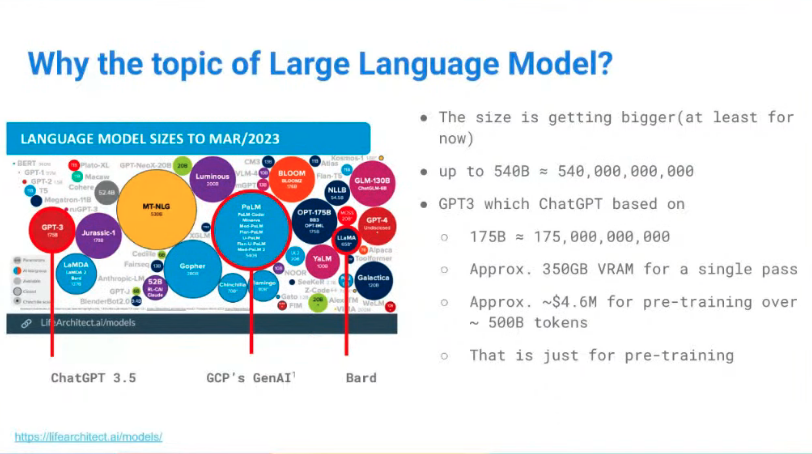
LLaMa 등장 후 모델 소형화 움직임도 있지만, 기본적인 방향은 Larger.
- ChatGPT 서비스의 모델인 GPT-3.5를 예로 들면
- 175 Billion 파라미터, half-precision 적용
- 모델 띄우는 데에만 350GB 그래픽 카드 메모리가 필요함.
- Serving 관점에서 사용자의 요청에 응답하고 내용을 저장한다? -> Inference 관점에서는 350GB도 부족함
- 학습 관점에서는 이거보다도 당연히 리소스가 더 필요함
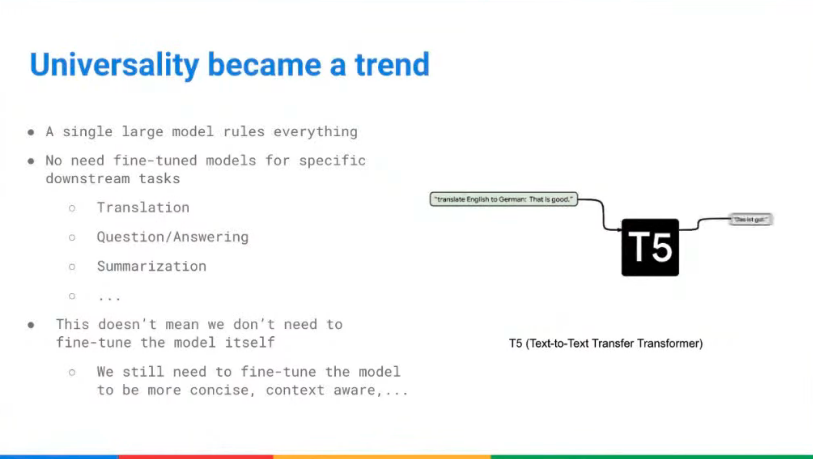
Bert, Transformer Architecture가 나올 때까지만 해도 Universal Model로서의 기대치는 없었다.
- pretrained layer가 있고, task-specific 한 계층을 쌓아서 특정 작업에 특화된 모델을 만드는 식으로 발전.
- pretrained된 부분은 freeze / task-specific한 부분만 fine-tuning 했기 때문에 비용이 크지 않았음.
- Text-to-Text Transfer가 나오고 나서부터의 변화 - "prompt만 잘 짜면, 어떤 작업이던 할 수 있다"
- 모델 자체가 universal solve -> fine tuning하기 매우 힘들어졌다
- 그렇다고 fine-tuning이 필요 없어졌냐? 라고 묻는다면 그건 아님.
- LLM 자체는 '문맥상 특정 단어 다음에 등장할 단어는 무엇인지를 예측'하는 방향으로 학습됨.
- 특정 도메인에 유용하도록 '글의 내용' 또는 '글의 표현방식'을 다듬거나, Hallucination 발생을 줄이기 위한 Fine-tuning은 여전히 유효함.
- 즉 LLM은 '세상을 이해하는 모델'이고, 내가 원하는 방식이 정해져 있다면 그 방식에 부합하도록 학습시키는 건 여전히 필요할 수 있음

Univeral Model (universality)은 이미 트렌드가 되었다.
GCP 환경에서 프리미엄 형태로 제공되는 Generative AI Studio 예시.
- Sentimental Analysis
- Classification
- Extraction
- Writing
- Ideation
등등 여러 가지가 있는데
들어가보면 전부 Prompt + Response 형태다. Generation Config (Temperature 같은 것) 을 얼마 줘야 하는지가 적혀 있는 정도. 즉 여러 가지 작업을 수행하는 방법은 똑같다.

운영 비용이 매우 비싸다. 서비스 maintenance 비용 엄청 들 것.
- modern deployment는 k8s / container (docker) / MSA 방식.
- stateless하고, scale Out이 용이하며, 쉽게 fail -> 복구 가능한 구조.
- LLM을 k8s / container 형태로 serving할 경우
- 엄청 무거운 프로세스이므로 containerize 시간이 오래 걸린다. container를 pull 받는 것도 오래 걸림
- 모델 버전이 올라갈 때마다 이 작업이 반복됨
- stateless, easy to fail / recover의 cost가 매우 크다.
- Instance를 고정적으로 유지한다... 사용자가 많아질수록 인스턴스가 추가로 필요하고, 비용이 엄청나게 올라감.
- 175B 파라미터가 있는 GPT3.5 모델을 GCP에서 10,000개의 인스턴스 고정으로 serving할 경우 $840,000,000/year

단순히 서버 띄우는 데만 저 정도인데, Inference 같은 기능은 돈 더 들어감. 수많은 사용자의 동시 요청... 어떻게 handling할 것인가?
- Pipeline Parallelism: 모델을 layer 단위로 쪼개서 병렬화.
- 모델이 더 커지면 Layer 단위로 쪼개도 processing time이 오래 걸린다.
- Tensor Parallelism: 계산 단위를 쪼개서 여러 GPU에 할당하는 식으로 병렬화.
- 병렬연산 결과를 취합해서 output tensor로 생성하는 식.
그럼 LLM의 Fine-tuning은 거대 기업만의 전유물일까?


개인 연구자 입장에서는 어떻게 해야 하나? 공부하고 연구하는 입장에서는 그 돈을 낼 수 없는데?
오픈소스 모델들이 많이 나왔다. 요즘은 매주 나오는 수준으로 쏟아지고 있음.
- Meta가 공개한 LLaMa가 신호탄.
- BigScience의 Bloom, EleutherAI의 Pythia, 영미권 말고 다른 언어의 foundation을 목적으로 나온 Polyglot 등등.
그렇다고 해도, 이 모델들의 pretrain은 불가능하다. 기술문제도 있지만 비용이 개인에게는 천문학적인 단위임.

pretrain의 목적은 Predict Text임. 문맥상 나오게 될 다음 단어가 무엇인지를 예측하기 위한 학습이지, 그 단어가 '사람에게 유용하도록' 학습하는 것이 아니다.
- fine-tuning은 모델에게 일종의 instruction을 제공하는 것
- "예시 답안"을 제공하면, 예시답안의 형식을 학습해서 해당 형식에 맞는 형태로 문자열을 생성하는 것.
- 이 fine-tuning만 놓고 보면 ChatGPT보다 그럴듯한 텍스트를 응답하는 모델도 많다.
- 오픈소스 진영에서는, 텍스트 품질만 놓고 보면 'ChatGPT처럼 만들겠다'는 목적을 위해 Reinforcement Learning Human Feedback (RLHF) 까지 할 필요는 없다고 생각하는 듯 함.
- 실제로 그런지는 잘 모르겠다. LLM이 응답하는 텍스트만 보면 그런 것처럼 보이는 것도 사실임.
Cost-effective fine-tuning 1. BitsAndBytes (a.k.a. LLM.int8())

핵심: 그래픽카드의 메모리를 최대한 효율적으로 사용하겠다.
- 결국 학습이란 Tensor 행렬연산의 연속임. 이 중에서는 bit연산이 많이 필요한 연산 / 많이 필요하지 않은 연산이 혼재되어 있을 것이다.
- 실행 시점에서 연산이 많이 필요한 것과 그렇지 않은 것을 outlier / non-outlier로 구분한다.
- 연산이 많이 필요한 (high-precision) outlier는 FP16
- 연산이 적게 필요한 (low-precision) 는 int8
- int8은 나중에 FP16 타입으로 변환
- 이 작업의 반복.
동적 연산이므로 메모리 효율성은 좋지만, 시간은 좀더 오래걸릴 수밖에 없음.
- HuggingFace에 포함되었고, load_in_8bit = True 옵션으로 쉽게 적용 가능.

다음주면 LLM.int4()가 가능할 것이라는 트윗.
- 이게 되면, 딥러닝 연산용 GPU 말고 일반 GPU로도 30B / 65B 수준의 LLaMa를 fine-tuning할 수 있게 된다!
Cost-effective fine-tuning 2. Parameter Efficient Fine-tuning (PEFT)


1번으로 어느 정도 비용효율화를 했다고 해도, 만족할 만한 성능을 얻으려면 수천 달러 이상은 필요하다. (i.e. 알파카 재단)
- 파라미터 조정해가면서 비교해야 하니까.
그래서 Parameter-efficient Fine-tuning 기법이 등장함.
- 오른쪽 상단 그림의 보라색 박스가 fine-tuning으로 값이 수정될 parameter들의 집합.
- 입출력 Dimension은 동일하게 맞춰주었을 때, 입출력 연산이 이루어지는 곱연산을 낮게 만들어줘도 성능이 괜찮더라. (by MS)
- Weight W의 변화량 = WA * WB의 곱연산이라고 했을 때
- WA = A * r-dimension, WB = r * B-Dimension 으로 정의함. 그리고 r이라는 dimension을 낮게 잡는다.
- WA와 WB만 학습시킨다는 발상.
- = 특정 layer에만 fine-tuning을 선택하는 등의 시도가 가능함. 학습 파라미터를 크게 줄여버린다.
알파카-LoRA 프로젝트는 r을 16 수준으로 낮게 잡았는데, 육안으로는 성능차이가 크지 않았다.
두 개를 결합하면? 적은 양의 리소스로도 가능하다
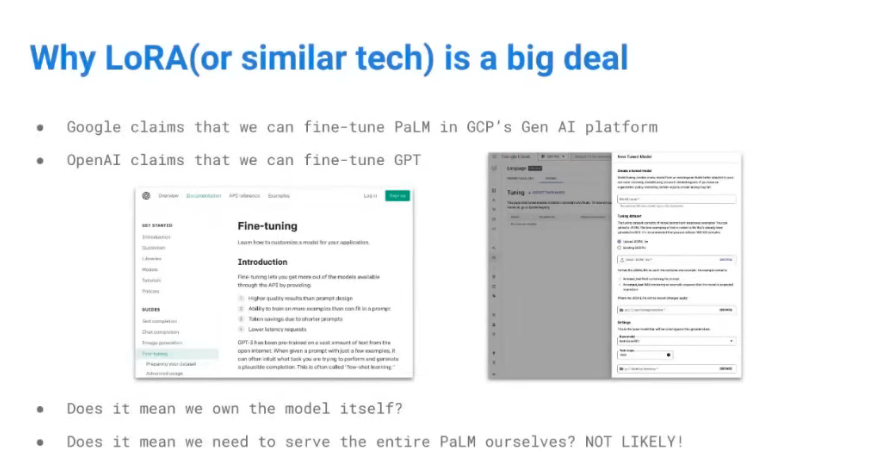
LoRA의 예시는 꽤 시사점이 많다.
- Google / OpenAI는 자사 서비스의 LLM을 Fine-tuning했다고 소개함.
- 그 거대한 LLM의 전체 파라미터를 fine-tuning했을까?
- 특정 작업의 성능이 뛰어날 수 있도록, 대응되는 파라미터만 학습시켰다고 보는 게 맞지 않을까?
OpenAI의 경우 GPT모델을 소유해서 돌리고 있으니... 인프라 레벨에서 굴리고 있을 것
- 사용자 입력값을 보고, 목적에 부합하는 특정 fine-tuned된 Layer로 전달하는 식의 최적화가 되어 있지 않았을까
Google은 자사의 PaLM을 fine-tuning하는 서비스를 제공하며, 몇 시간이면 된다고 함.
- 그 거대한 모델의 모든 파라미터를 fine-tuning하는데... 몇 시간 수준으로 해결될 수 없음
퍼블릭 클라우드에서는 이런 형태의 서비스가 등장할 가능성이 큼. 모델을 직접 소유하는 형태가 아니라 fine-tuned된 파라미터를 소유하는 형태의 서비스.


오픈소스 진영에서 이 기술들이 많이 쓰이고 있음. huggingface에서도 PEFT가 시작된 지 얼마 되진 않음.
- LoRA는 LLM을 위해 나온 최적화기법이 아니긴 함. 앞으로 더 좋은 기술이 나오면, 그걸 사용하는 식으로 흘러가지 않을까
Alpaca-LoRA는 이 기술로 RTX 4090로도 30B 파라미터까지 fine-tuning 성공함.
- 하루 정도 걸렸다고 함
- 코드도 매우 단순함. 기존 transformers에서 사용하던 학습 방식과 비슷.
- 결과물 적용도 쉬웠다고 함.

학습에 더 유용한 기술인 BetterTransformers / Optimum의 등장.
- cf. 여긴 내가 이해를 못해서 적을 게 없다
단점
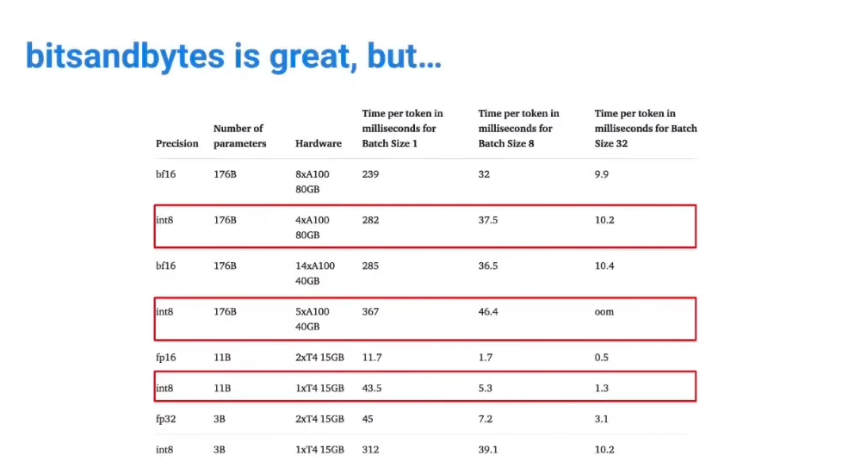
Inference에는 좋지 않다. Dynamic하게 연산량 비교하는 작업 때문.
- 학습에서는 감내 가능한 요인이지만, 서비스 관점에서는 감내하면 안 되는 영역.
- 서비스할 모델은 FP16 등으로 precision 통일해서 serving하는 게 맞다
Deployment / Serving : Streaming vs Batch

streaming이 UX 관점에서는 좋긴 한데, 효율성 입장에서는 애매하다. ChatGPT의 응답방식이 streaming, Bard의 응답방식이 Batch.
- streaming 특성상 여러 Request를 합쳐서 하나의 프로세스로 처리하지 못함. Request by Request.
- bard의 경우 하나의 request에 여러 개의 응답을 한 번에 돌려줄 수 있다.
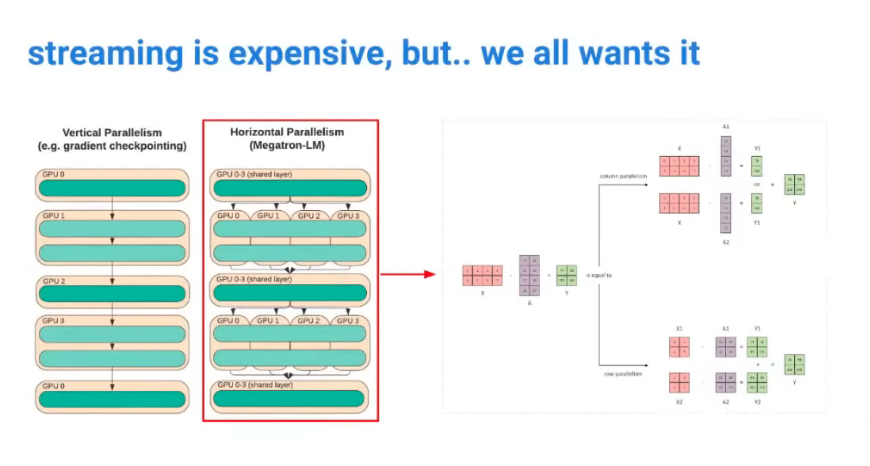
Streaming 방식을 사용해서 서비스한다고 하면
- Layer 병렬처리의 효율이 떨어짐. Layer 연산이 무거워서, 병렬처리를 해도 프로세스가 대기하는 시간이 생길 수 있기 때문.
- Tensor 자체를 병렬화해서 속도를 더 높이고 대기시간을 줄이는 방식이 낫다.
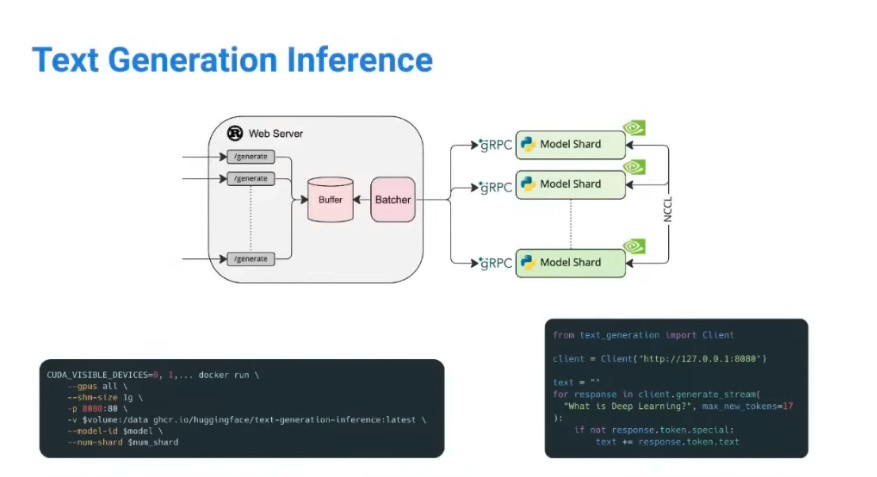
일부 유명한 모델에 한해서 이걸 쉽게 쓸 수 있는 HuggingFace Framework가 있음. huggingface의 model 소개 페이지에서 text generation을 쉽게 테스트해볼 수 있는 Web UI가 있는데, 십중팔구 이걸 쓰고 있다.
- docker image 형태 / Python Client library 형태로 지원하고 있음
Building a General Framework for different LLMs
어떤 LLM 모델이 더 좋은지 비교할 수 있나?


오픈소스 진영에서는 다들 자기네 LLM이 ChatGPT보다 낫다고 주장한다.
- 그러면서 보여주는 예시는 보통 잘 나온 것만 취사선택해서 보여줌.
- 예시만 보면 괜찮은데, 나만의 Usecase에 적용해보면 기대 이하인 경우가 많음.
- Academic BenchMark 값과 Commercial Use 결과에는 괴리가 큼
- Commercial Use일 경우
- 상업적으로 쓸 수 없는 모델이면 안 되고 (i.e. LLaMa)
- GPT가 생성한 데이터로 모델을 학습한 경우 상업적으로 사용할 수 없음 - Fine-tuning에 사용한 데이터도 상업적 문제가 없어야 함
- 따라서 오픈소스를 토대로 LLM을 상업적 사용하는 건 현재로서는 어렵다.
Vicuna
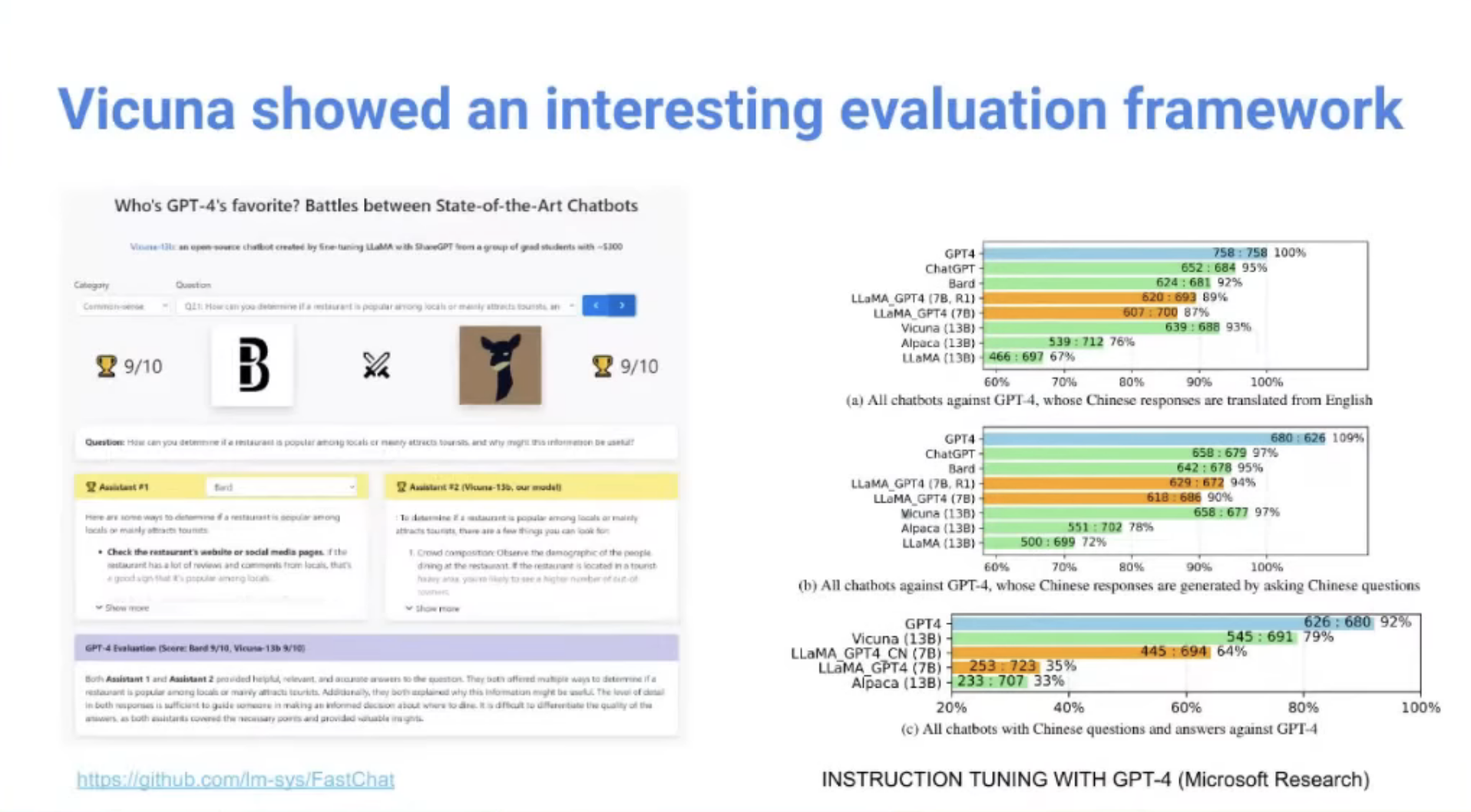
LLM 모델의 Validation을 위한 Vicuna
- GPT4에게 '어떤 모델이 생성한 결과가 가장 좋은가'를 10점 만점 기준으로 물어본 것.
- 이것도 단순히 '생성결과'만을 놓고 비교한 거고, 실 서비스에서 '완성도 있게' 제공하는지를 판단하기 위한 기준은 또 다를 것.
- 윤리적 이슈
- Hallucination
그래도 이 결과에서 재미있는 점
- Vicuna는 LLaMa 기반 fine-tuned된 모델. 근데 왜 결과 숫자가 잘나왔나?
- 사용한 데이터: SharedGPT 사이트에서, 사람들이 GPT의 conversation 결과 중 흥미로운 것들을 공유한 데이터를 학습함
- 보통 학습할 때 instruction - Response 형식 데이터만 학습하는데, 여기 데이터는 Conversation (Human / GPT를 Sequential하게 나열한 것) 임.
개인적인 시도 (서비스)
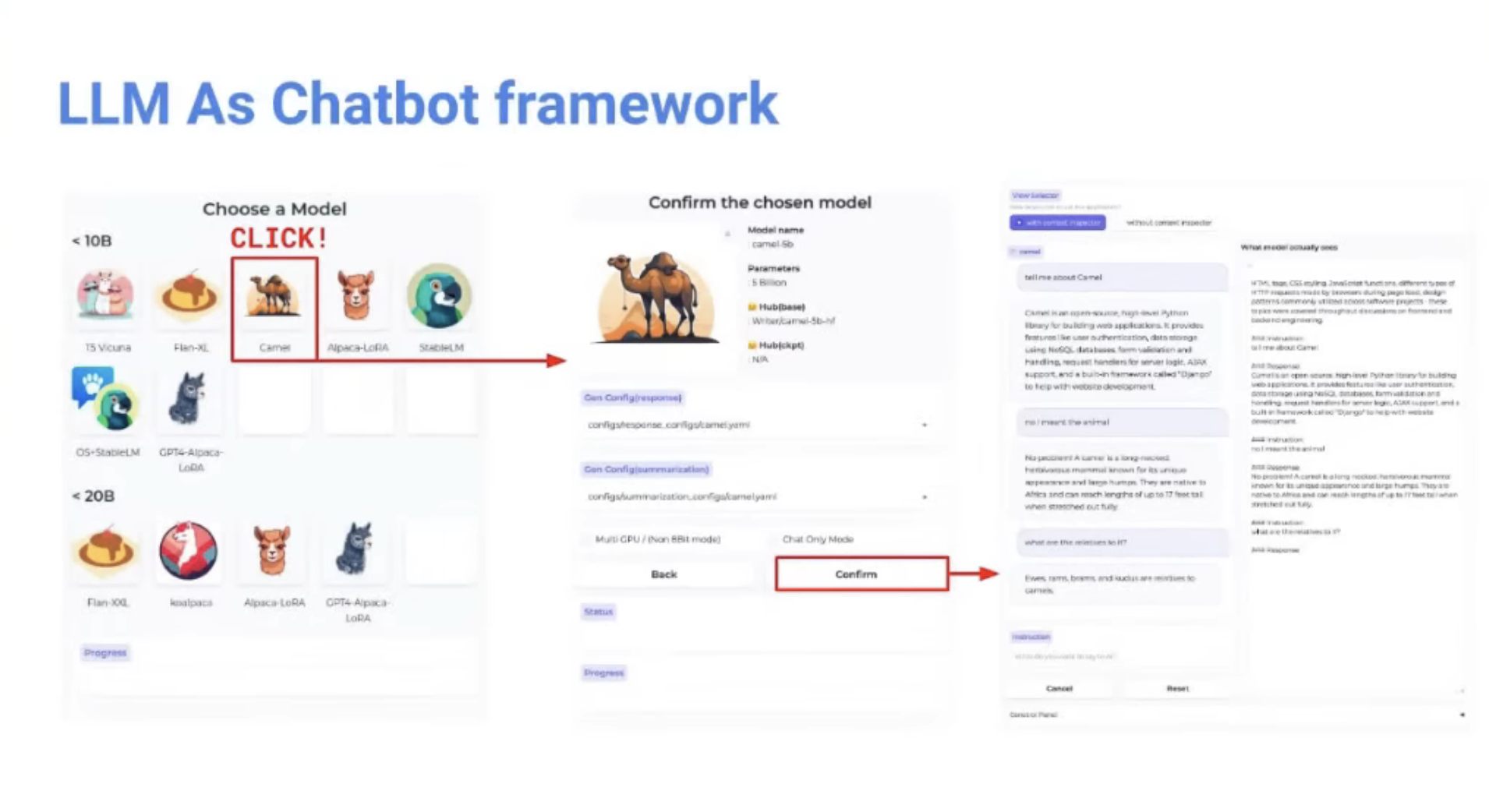

개인적으로 하고 있으시다는 프로젝트: LLM을 playground 형태로 써볼 수 있는 서비스
- 해결하고자 하는 문제
- LLM 오픈소스는 많은데, 각 오픈소스가 Fine-tune 진행한 prompt 구조가 전부 다름
- 모델의 입력form과 오픈소스에서 제공하는 UI의 form이 다름. 관리가 어려움
- 어려웠던 점
- 로그 확인 (모델에 들어가는 Prompt가 어떻게 구성됐는가)
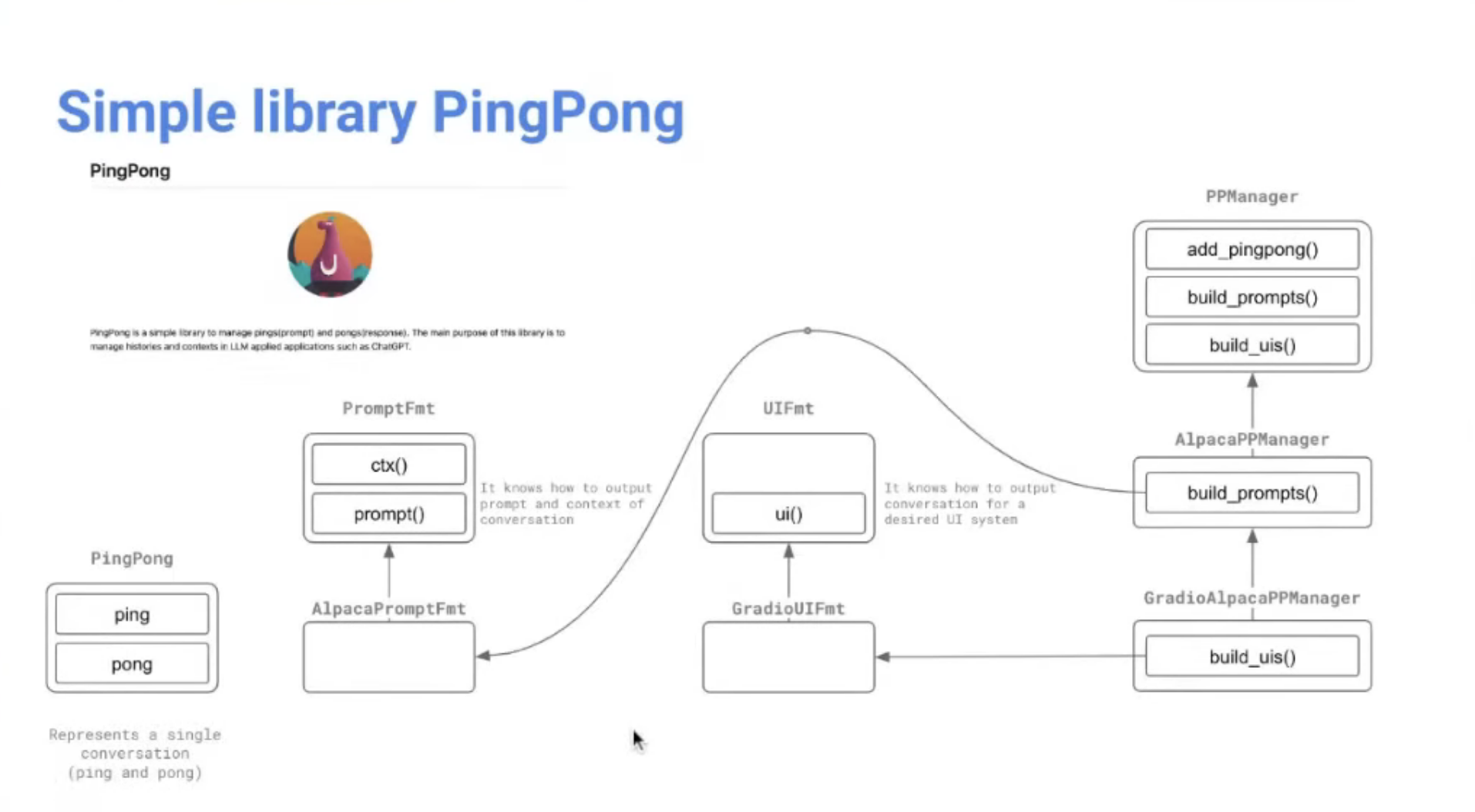
예시: ping (사용자 입력) / pong (LLM 응답)
- 사용자가 Ping + pong을 넣으면, 해당 LLM 모델이 어떤 Prompt로 생성했는지 해석? 유추? 하는 것
- UI framework에서 사용할 수 있는 포맷으로 변환해주는 기능도 포함.
- PRManager: conversation 형태로도 구성할 수 있게.
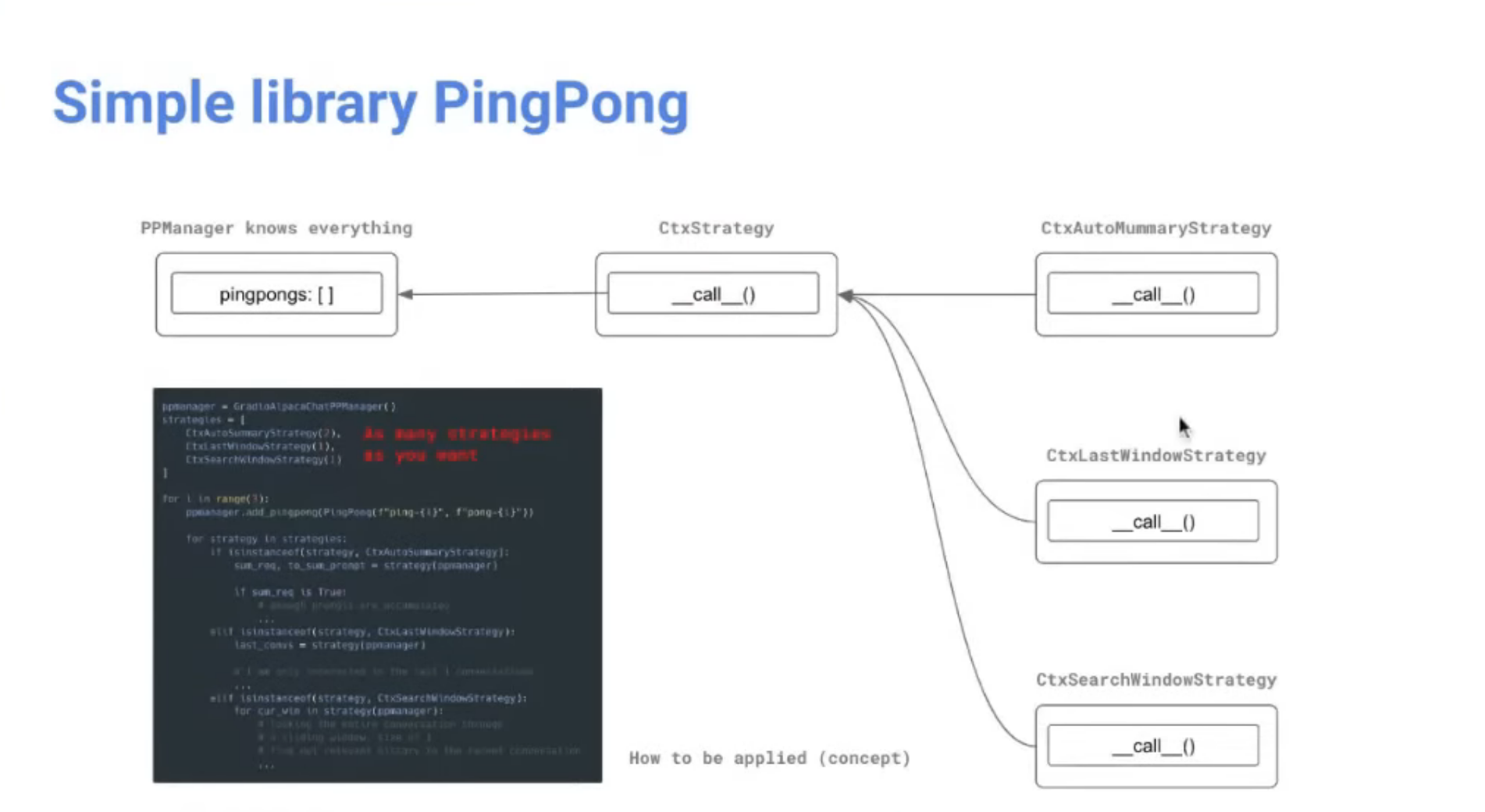
Strategy 몇 가지 제공 (i.e. lastWindow: 대화를 진행할 때, 직전에 했던 대화 몇 개는 반드시 포함한다)
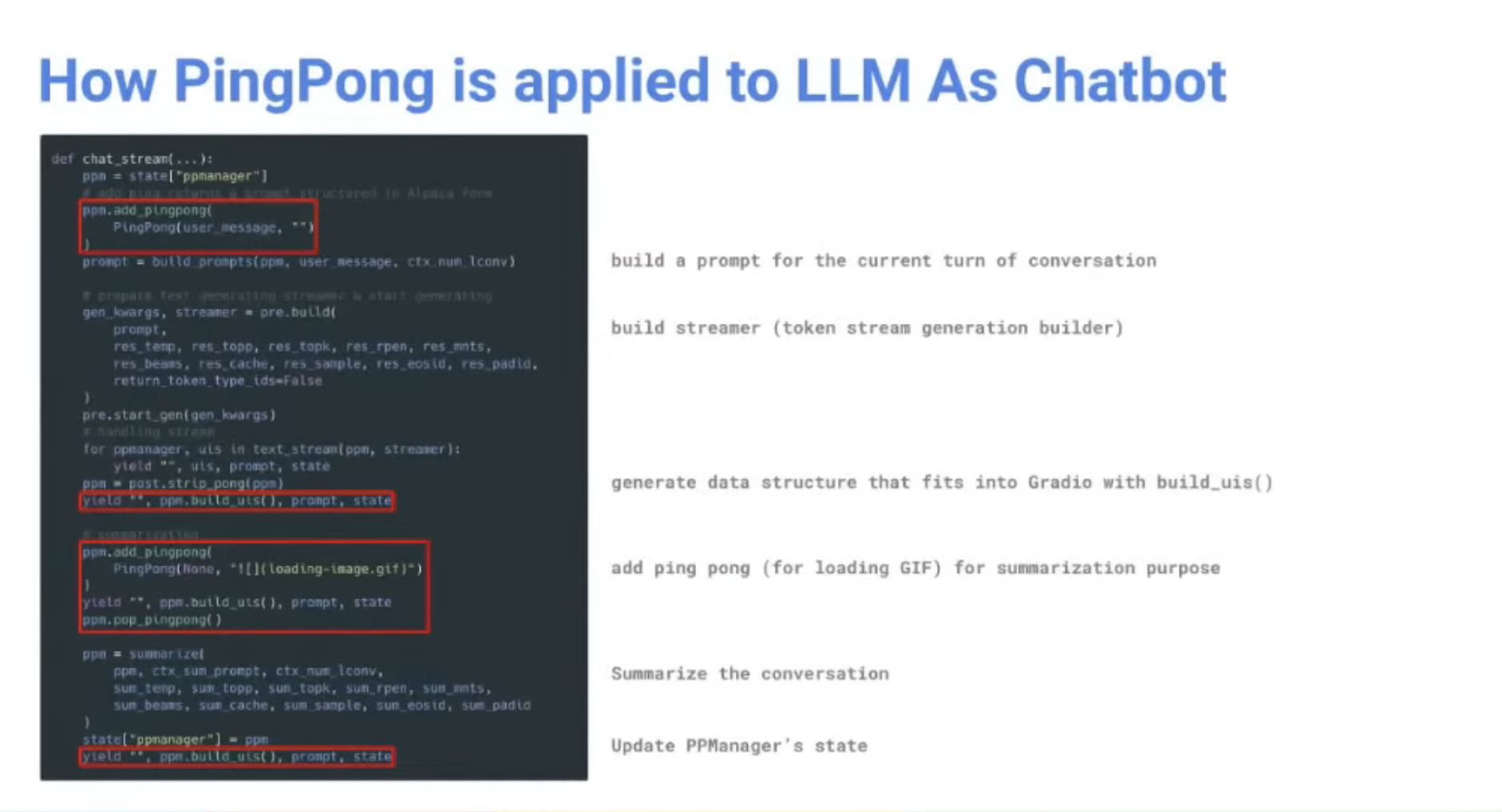
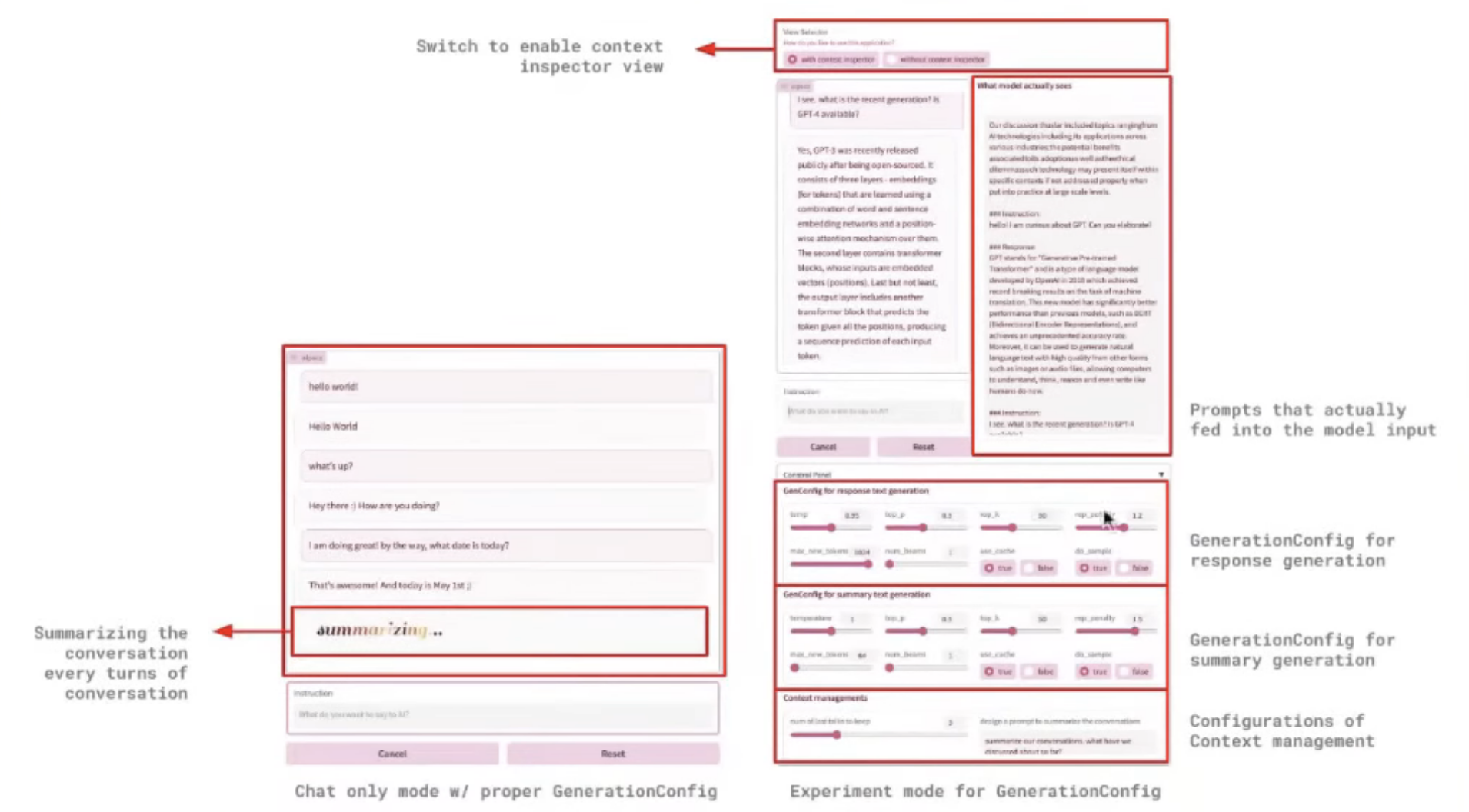
진행해볼 것들
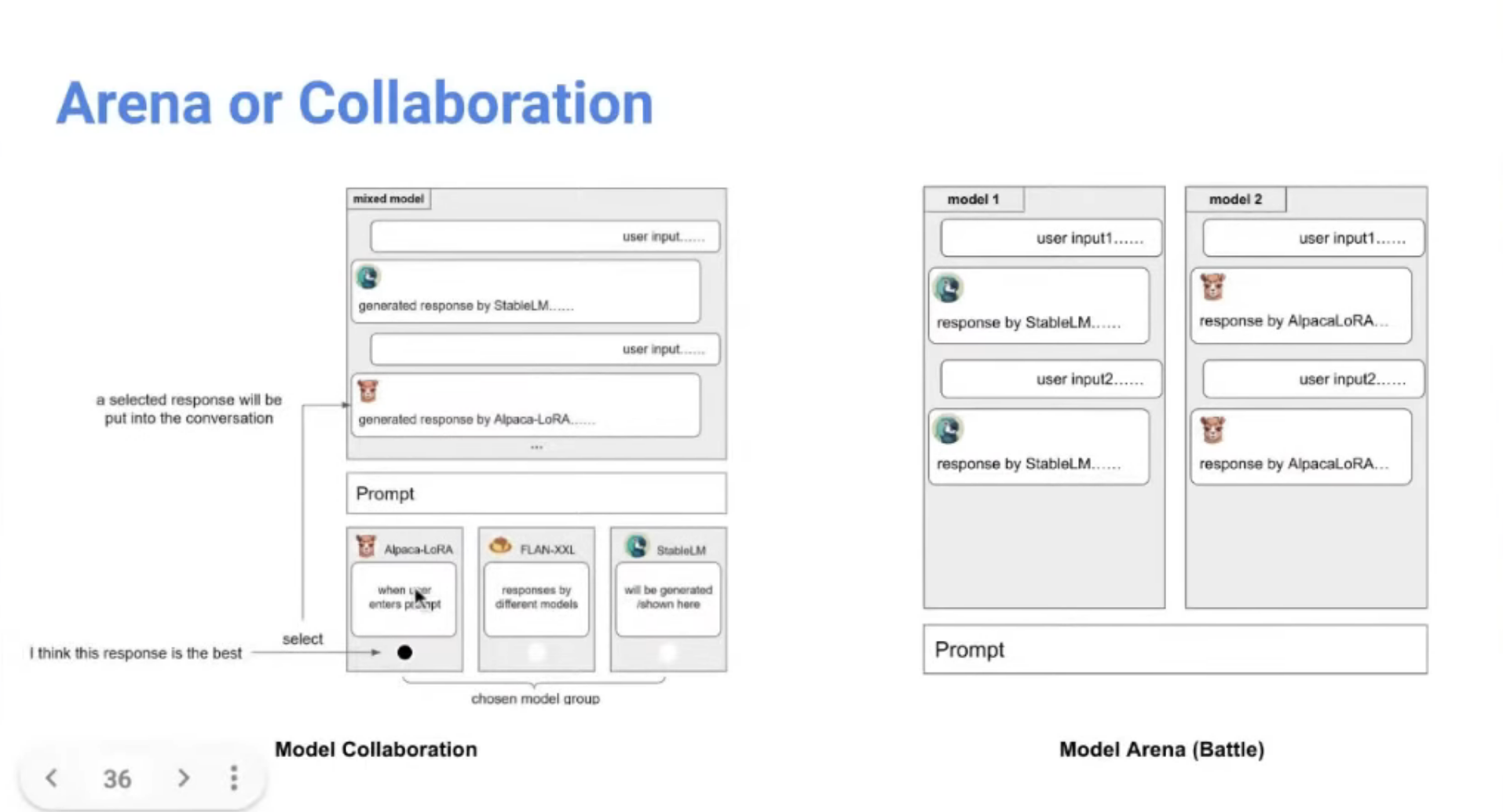
오픈소스 모델을
- Arena: Vicuna의 Arena처럼 동일 prompt 주고 어떤 대답을 하는지 비교하기
- Collaboration: 각 LLM이 내뱉는 응답을 합쳐서 하나의 완성된 응답을 제공하는 UX

로컬에서 실행하는 LLM과 Remote로 실행하는 LLM이 동일한 API 구조를 사용하도록 하기
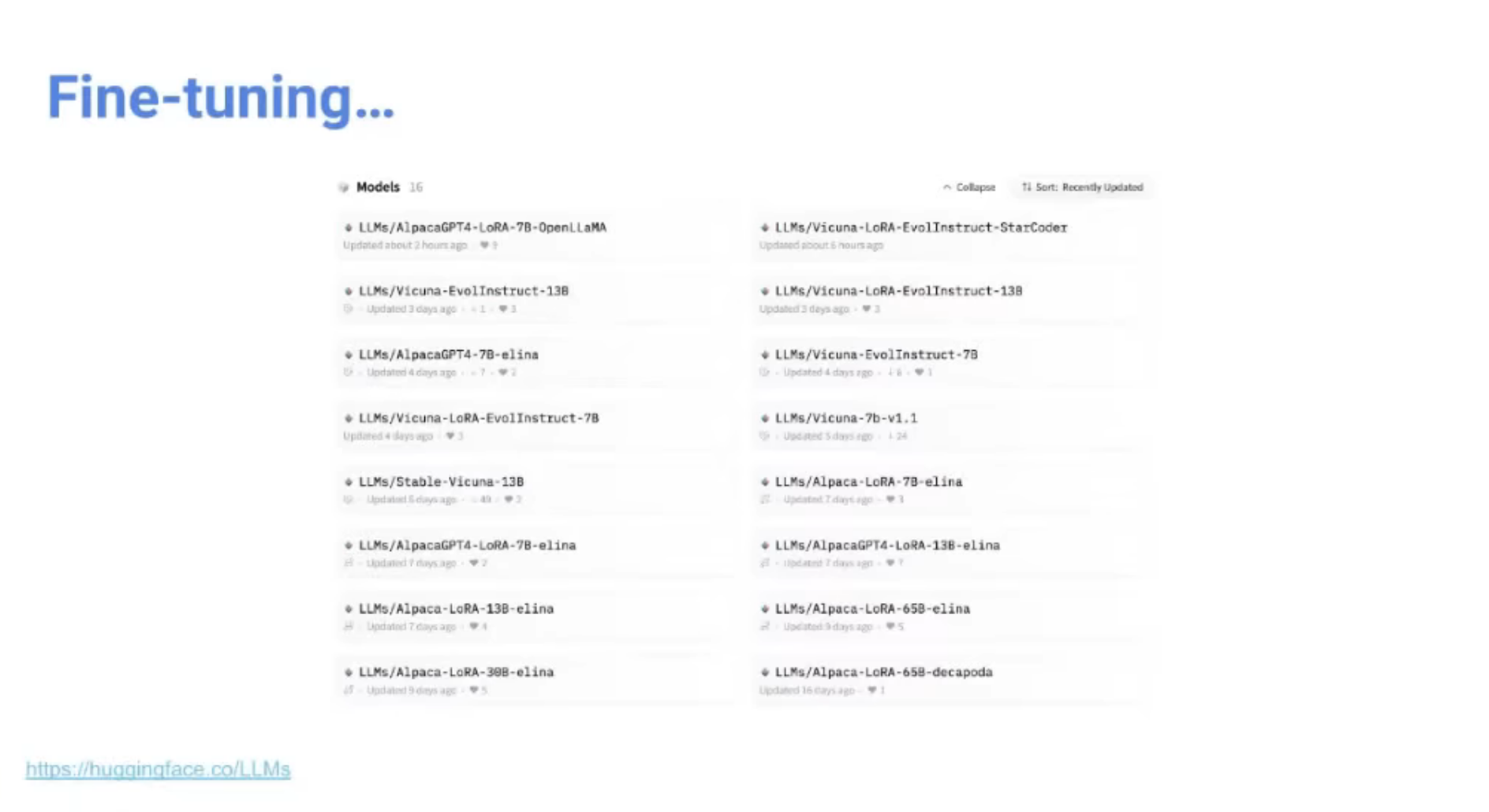
수없이 등장하는 데이터셋 / LLM... Fine-Tune 해봐야 함.
- HuggingFace에 LLMs라는 레포 파서, fine-tuning 진행한 모델 올리고 있음.

Commerical Free한 데이터 generation.
- commercial free한 데이터셋의 대표 예시인 Dolly. 그러나 이걸로 학습시킨 LLM의 응답결과는 만족스럽지 않다
- 이게 있으면, Commercial Free인 데이터로 학습했기에 상업적 사용에도 문제 없으며 성능도 좋은 오픈소스 LLM을 만들 수 있지 않을까 기대중