서울시 생성AI 해커톤 후기
(공모2) 생성형 AI를 활용한 상담지원 서비스 앱・웹 개발
aifactory.space
기획 / 아이디어
아이디어는 공고에 첨부되어 있던 '다산콜센터 상담 프로세스'의 위 페이지 한 장에서 완성됐다.
- LLM에서 기술적으로 성능이 검증된 기능 중 하나가 '문해력'이다.
- 긴 글의 맥락 이해, 문서 요약과 같은 작업의 수행 능력이 뛰어나다.
- 일평균 2만 건을 사람이 직접 처리하고 있다면, 자동화를 제안할 명분으로는 충분했다.
- LangChain을 활용하면 LLM을 활용한 로직을 소스코드로 자동화할 수 있다.
- LangChain을 사용한 Summarize Chain 활용법은 이미 유튜브에 많이 공개되어 있다.
- HuggingFaceHub의 오픈소스 모델로 구현하면 ChatGPT 사용료를 내지 않아도 된다.
- 상담 음성을 텍스트로 변환(Speech to text)하고, 변환된 텍스트를 LLM으로 요약시키면 되겠다.
그래서 'LLM 기반 상담내용 자동요약 서비스'를 주제로 잡았다.
LLM이라는 도구와 '상담요약'이라는 문제를 찾았으니, 제출할 수 있는 '기획서'의 형태를 만들기 위해서는
- 내가 제안할 '상담요약의 자동화 서비스'가 왜 필요한가? 라는 질문에 답변할 논리와 명분을 구성해야 했다.
해커톤의 주제를 정할 때 가장 공들이는 부분이 이 '논리와 명분'을 만드는 것이었다.
- 테크를 주제로 한 해커톤이지만, 보통 모든 심사위원이 해당 기술 전문가로만 구성되진 않는다.
- 또 해커톤 발표는 테크밋업이 아니기 때문에,
기술의 당위성을 소개하는 것보다 '해결해야 할 문제'를 설득하는 편이 항상 더 쉬웠다.
- 또 해커톤 발표는 테크밋업이 아니기 때문에,
- 난 항상 '심사위원은 내가 제출한 기획서를 읽지 않은 채 발표를 듣는다'고 전제한 채 발표를 준비했다.
- 제한된 발표시간에 기획, 구현방법, 효과를 전부 납득시키면 좋지만, 생각보다 그거 쉽지 않다.
- 그러면 '논리와 명분' 하나만이라도 뇌리에 박히게 만들면 된다.
원래 기획서 쓸 때 가장 시간이 오래 걸리는 부분인데, 시간이 별로 없어서 가성비 좋은 구조만 세웠다.
- 왜 상담요약을 자동화해야 하나?
- 가장 큰 목적: 이미 다산콜센터 상담사가 느끼는 업무 부담이 큰 상태다.
- 부가적인 이유: 생성AI를 활용한 공공기관 업무환경 개선사례로 활용할 수 있다.
- 해커톤 주최기관인 '서울디지털재단'의 최근 보도자료를 찾아보니 ChatGPT 활용한 홍보가 많았다.
- 발표할 때 지나가듯이 언급해주는 정도로 어필해도 효과가 있을 거라 생각했다.
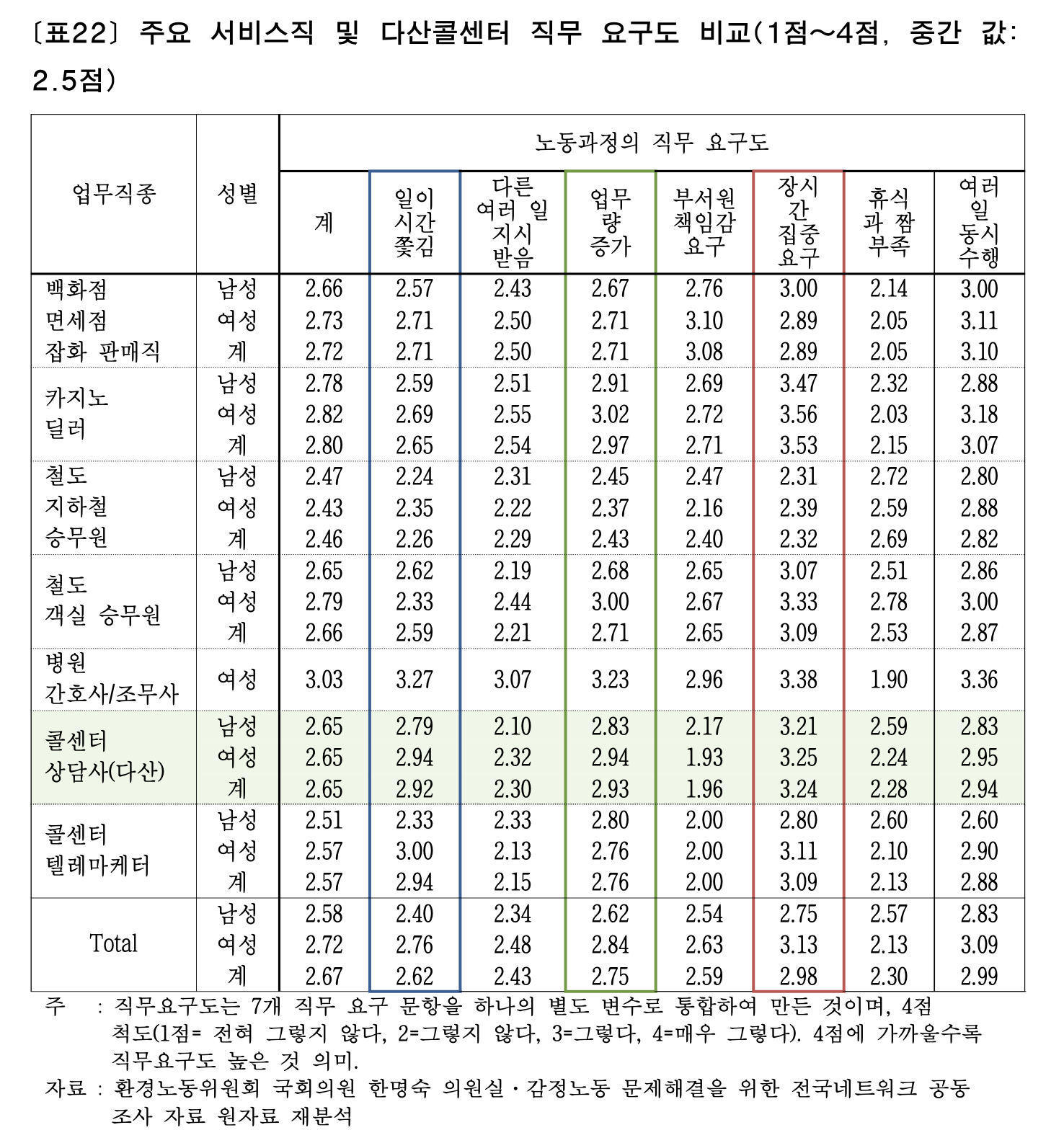
고맙게도 다산콜센터 상담사의 노동강도나 업무환경을 조사한 자료가 있었다.
- "김종진.송민지. (2013). 서울시 120다산콜센터 감정노동과 고용구조의 합리적 해결방안 모색"
- '상담사의 업무 부담이 크다' 라는 주장의 근거로 여기 있는 자료를 활용했다.
- 10년 전 자료라는 한계가 있지만, 근거가 없는 것보다는 훨씬 낫다고 봤다.
그렇게 만들어진 최종 아이디어를 한 줄로 표현하면
- '다산콜센터 상담원의 업무부담을 낮추기 위해, LLM을 활용한 상담요약 자동화 시스템'을 개발한다.
구현
소스코드는 https://github.com/AIFactory-CallPilot/CallPilot 에서 확인할 수 있다.
구현할 기능은 크게 네 가지였다.
- 상담 음성을 Object Storage에 업로드하고, 메타데이터를 Database에 저장하는 기능 (upload)
- 상담 음성을 Speech to Text 수행하고, 결과물을 Database에 저장하는 기능 (stt-by-api)
- Speech to Text 결과물을 LLM으로 요약하고, 요약 결과를 Database에 저장하는 기능 (summarize-llm)
- 요약 결과를 조회하는 기능 (get-response)
원래는 AWS를 활용하려 했는데, GCP의 Free Credit으로 GPU를 발급받아서 테스트할 수 있었기 때문에 GCP를 활용했다.
- 그러나 Colab에 GCP Hosted VM을 붙여도 HuggingFaceHub에서 모델을 불러오면 timeout이 발생했다.
- 오픈소스 LLM을 사용하면 ChatGPT와 같은 상용API 대비 한계비용이 낮아진다는 점을 강조하고 싶었는데, 여건이 되지 않았다.
Speech to Text와 LLM의 경우 OpenAI의 상용 API (Whisper, ChatGPT) 를 사용했다.
- 서비스 특성상 응답속도가 중요한데, Colab에서 제공하는 nvidia T4 GPU보다 상용 API 응답속도가 더 빠름.
- 해커톤 시연 용도로 고성능의 GPU를 할당받기엔 비용이 너무 비싸다
GCP에서 사용한 서비스는 아래와 같다. 아래 서비스 전부 일정 quota까지는 무료이고, quota 초과해도 Free Credit으로 정산할 수 있는 서비스들이었다.
- Storage
- Cloud Storage: 상담 음성 (mp3 파일)을 저장할 Object Storage. 시연에 쓸 static web page hosting 용도로도 썼다.
- Cloud Firestore: 상담 음성 메타데이터, Speech to Text 결과물, LLM 요약 결과를 저장하는 Serverless NoSQL Database.
- Process
- Cloud Functions: 상담 음성을 업로드하는 HTTP Endpoint / Speech to Text를 수행하는 Process 구현
- Cloud Run: LLM 요약 기능을 수행하는 Process / 요약 결과를 조회하는 HTTP Endpoint 구현
- Q. Cloud Functions 하나만 써도 될 텐데 왜 Cloud Run도 같이 썼나?
- A1. Cloud Functions는 기능상 Path Parameter를 지원하지 않았다.
- 업로드된 mp3 파일명을 Path parameter로 GET 요청을 보내 요약 결과를 가져오도록 하고 싶었는데, 그러려면 CloudRun 써서 직접 API 서버를 만들어야 했다.
- A2. 원래는 오픈소스 LLM에 GPU를 붙여서 동작하도록 만드려 했고, 그러려면 GPU 머신 위에서 돌아갈 수 있는 Container 형태로 서비스를 구현해야 했다.
- 오픈소스 LLM이 아니라 ChatGPT API를 쓰게 되면서, 만들어뒀던 Dockerfile을 그대로 쓸 수 있는 CloudRun을 활용했다.
- Pipeline
- Cloud Workflows: 특정 Event를 Trigger로 내가 원하는 프로세스를 순차적으로 / 병렬로 실행할 수 있게 해 주는 pipeline.
- Cloud Storage에 파일이 업로드되면 Speech to Text -> LLM Summarize를 순차적으로 실행할 수 있게 만들 수 있어서 유용하게 활용했다.
- Cloud Workflows: 특정 Event를 Trigger로 내가 원하는 프로세스를 순차적으로 / 병렬로 실행할 수 있게 해 주는 pipeline.
시연에 사용한 데이터는 AIhub에서 제공하는 민원(콜센터) 질의-응답 데이터 였다.
- 카테고리는 "코로나19 / 일반행정 / 대중교통 / 생활하수도 관련 문의" 네 가지.
- 상담 최대길이가 3분을 넘지 않는 데이터만 있었고 파일 크기도 작아서, OpenAI Whipser 상용 API 제한에도 걸리지 않았다.
- (OpenAI Whisper 상용 API는 1회 호출 시 25MB 미만의 음성 데이터만 처리할 수 있었다.)
Prompt Engineering에서는 특별한 게 없었다.
- 시간상 Speech to Text를 수행할 때 화자 구분(Dialization)까지 만들 수는 없었기 때문에, input text가 '고객과 상담원의 대화'라는 것을 LLM에 주지시키고
- 상담을 관통하는 핵심 질문 1개 / 그 질문의 답변을 간결하게 요약하도록 지시했다.
- concise라는 키워드와 글자수를 특정 bytes 넘지 않도록 조건을 추가했더니 꽤 성능이 괜찮았다.
결과
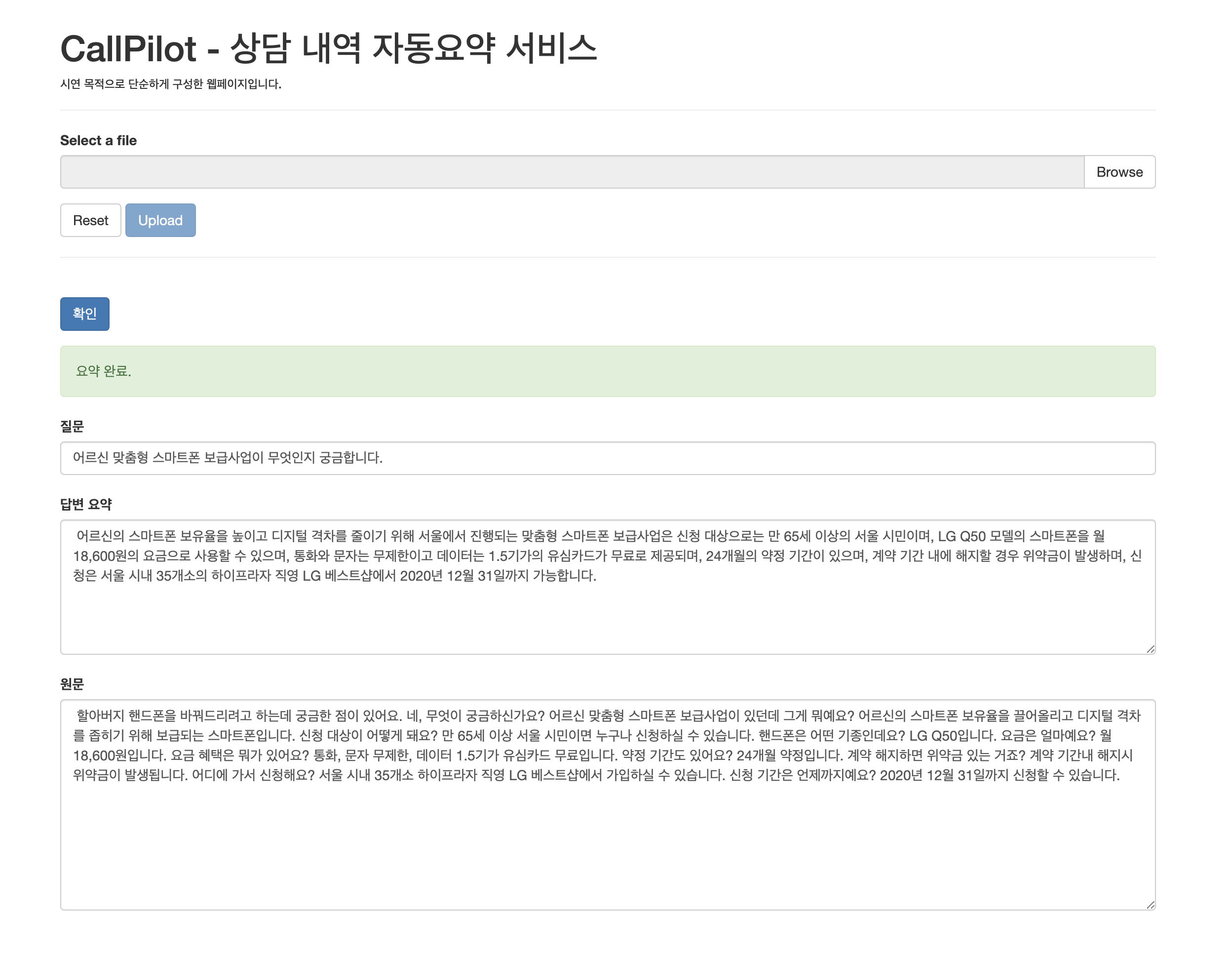
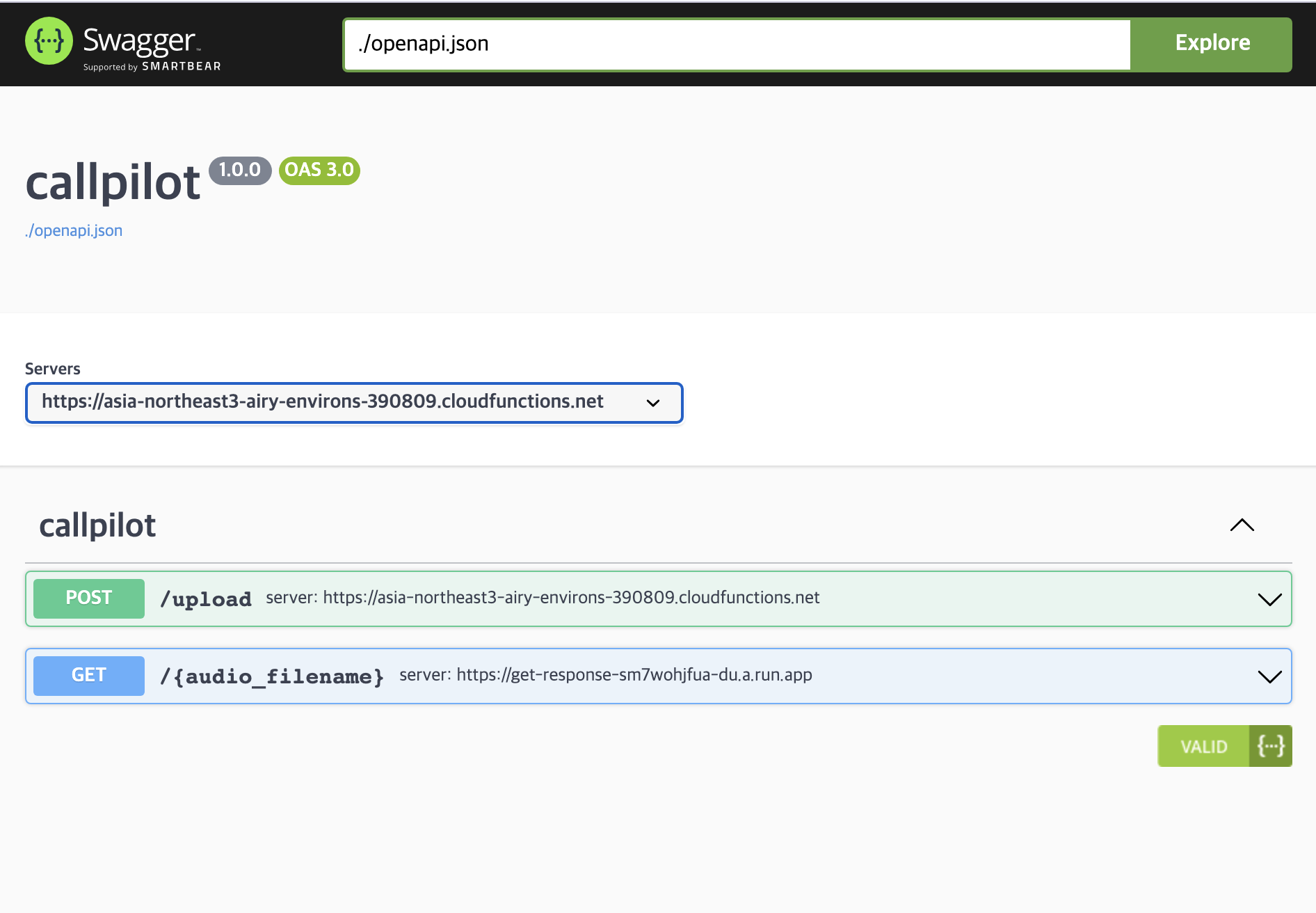

GCP 중에서도 처음 써 보는 Cloud Workflows가 약간 시간이 걸렸다.
- 특히 Workflow에서 GPU 머신 할당받을 수 있는지 테스트하느라..
- 이건 공식문서에 예시가 친절하게 써 있던 건 아니었어서, Compute Engine이나 job API 문서에서 gpu 관련된 파라미터들을 일일이 확인해야 했다.
아이디어 자체는 딱히 창의적인 부분이 없었지만, 기획서에서 제안한 기능을 완성해서 시연까지 했던 것이 좋게 평가받았던 것 같다.
'프로그래밍 > 이것저것_개발일지' 카테고리의 다른 글
| Python SQLAlchemy의 many to many relation에 soft delete 기능 적용하기 (0) | 2024.03.25 |
|---|---|
| FastAPI, SQLAlchemy 프로덕트에서 alembic을 쓰지 않은 이유 (0) | 2024.01.29 |
| Paketo buildpack의 Stack Customization 테스트 기록 (0) | 2023.04.12 |
| Streamlink로 유튜브 멤버십 스트리밍 영상 다운로드하기 (2) | 2021.09.27 |
| 화상 모의면접 연습 플랫폼 개발 프로젝트 (2) - KeyCloak 활용해서 서비스 DB에 OAuth 인증 붙이기 (0) | 2021.04.18 |